Hadoop
Résumé de section
-
-
Hadoop is an open source software framework for storage and processing large scale of datasets on clusters of hardware.
Hadoop provides a reliable shared storage and analysis system, here storage provided by HDFS and analysis provided by MapReduce.

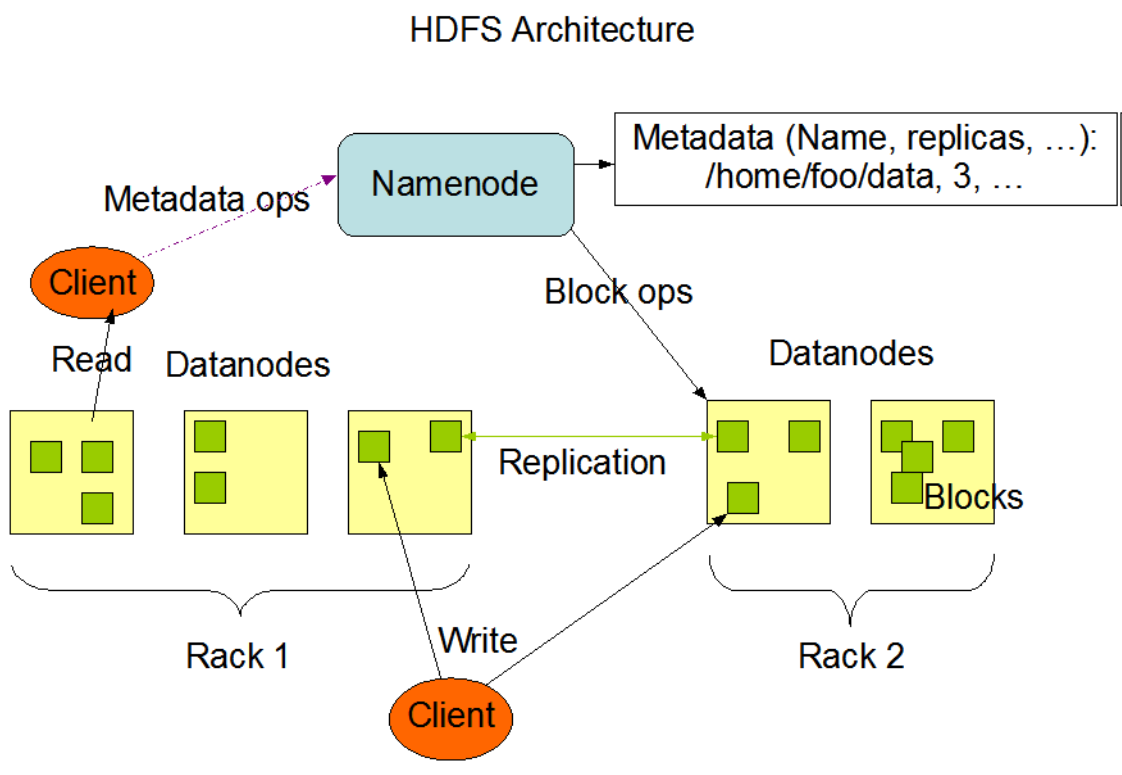
1- HADOOP DISTRIBUTED FILE SYSTEM (HDFS):
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on hardware.
It has many similarities with existing distributed file systems.
HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.
HDFS provides high throughput access to application data and is suitable for applications that have large data sets.
NameNode and DataNodes
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system name space and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system name space operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. TheDataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation,deletion, and replication upon instruction from the NameNode.
The NameNode and DataNode are pieces of software designed to run on commodity machines. These machines typically run a GNU/Linuxoperating system (OS). HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNodesoftware. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment hasa dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNodesoftware. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator andrepository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
The File System Namespace
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories.The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from onedirectory to another, or rename a file. HDFS supports user quotas and access permissions. HDFS does not support hard links or soft links.However, the HDFS architecture does not preclude implementing these features.
While HDFS follows naming convention of the FileSystem, some paths and names (e.g. /.reserved and .snapshot ) are reserved. Features suchas transparent encryption and snapshot use reserved paths.
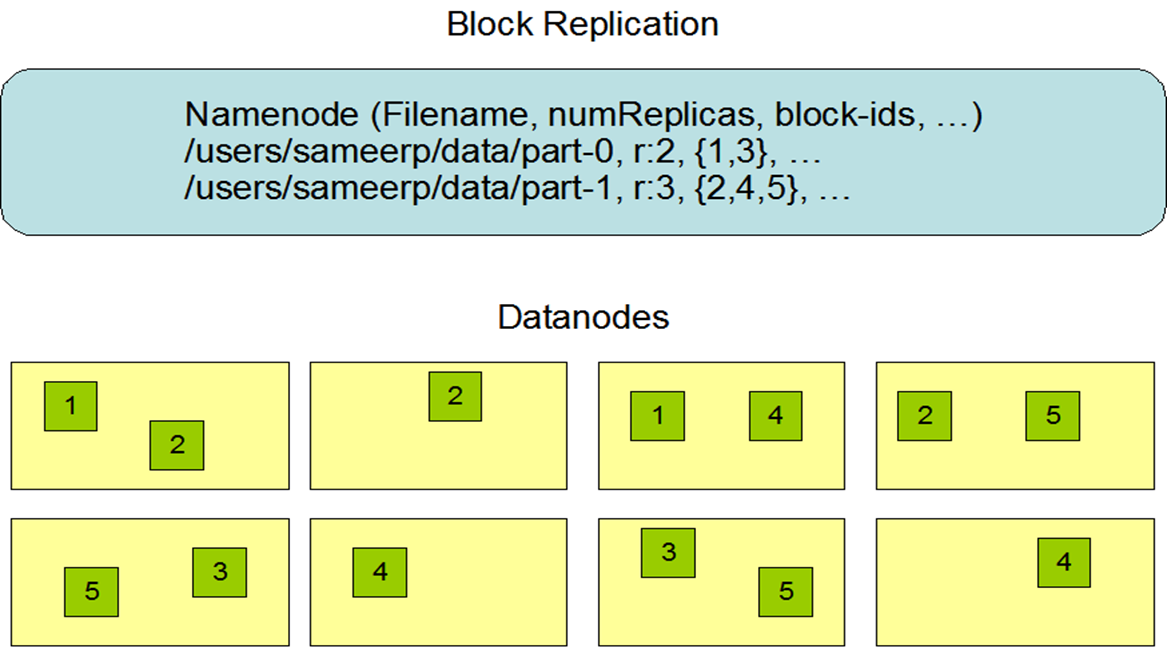
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode.An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called thereplication factor of that file. This information is stored by the NameNode.
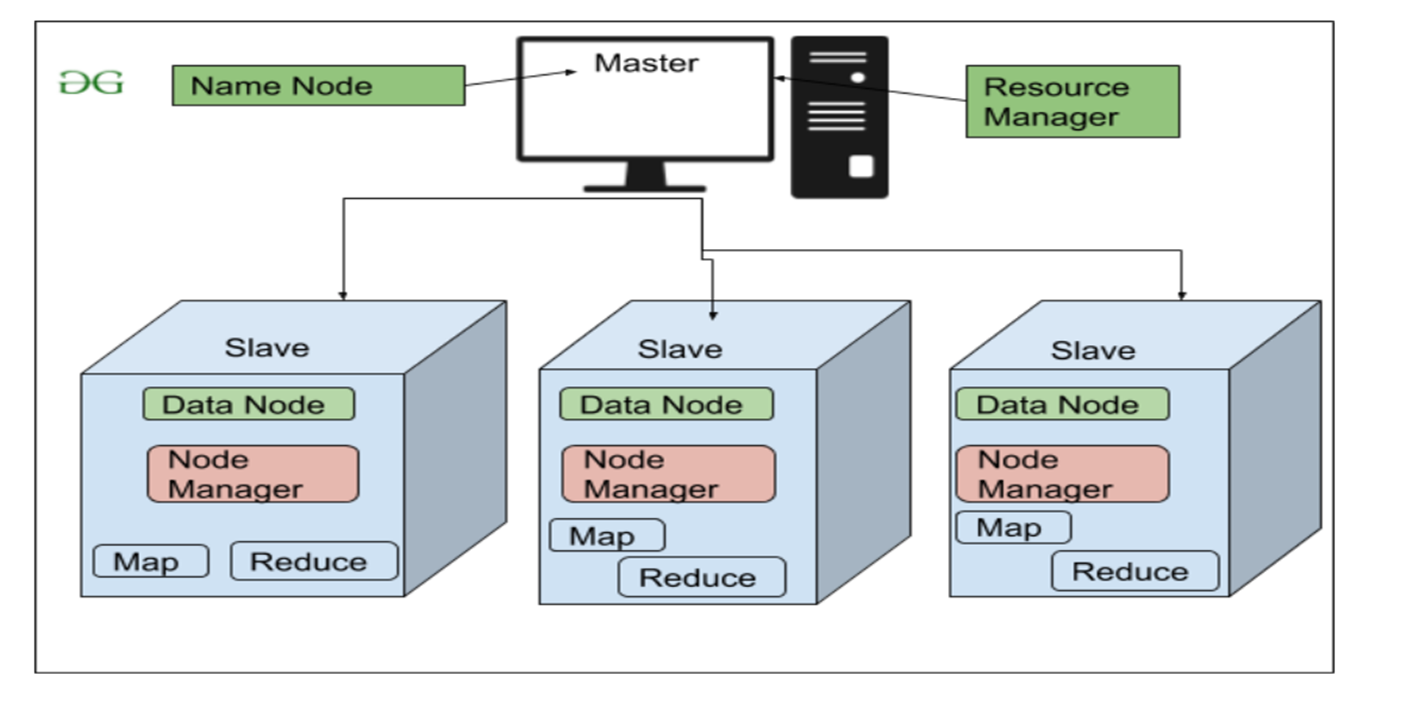
2- MapReduce:
It origins from Google and helps to divide complex computing tasks into more manageable subprocesses and then distributes these across several systems, i.e. scale them horizontally. This significantly reduces computing time. In the end, the results of the subtasks have to be combined again into the overall result.
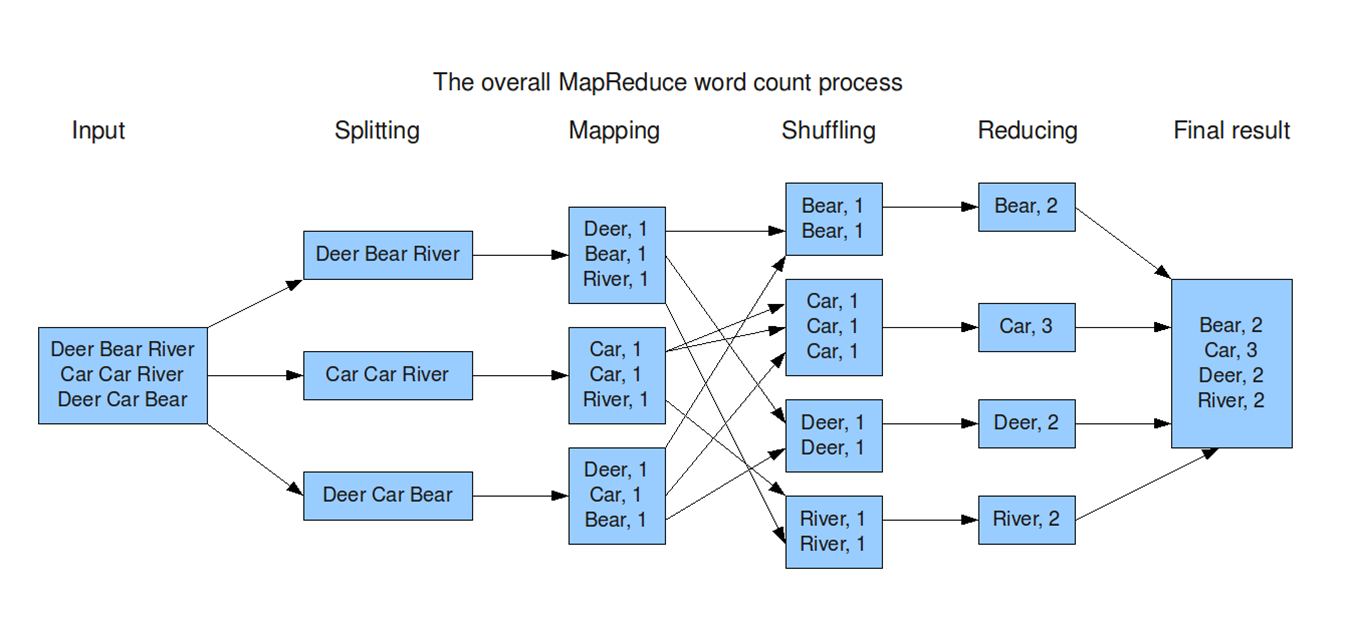
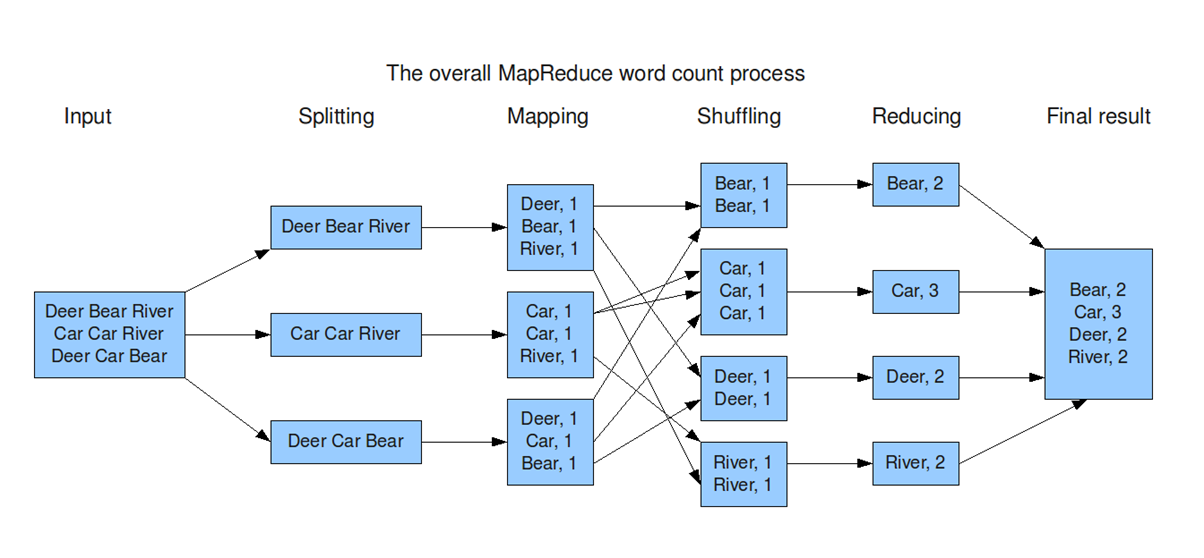
Input:The system takes a large dataset (e.g., a file or database) as input for processing.
Splitting:The dataset is divided into smaller chunks (splits) to be processed in parallel across multiple nodes.
Mapping:Each chunk is processed to generate key-value pairs, where the key organizes the data, and the value provides relevant information.
Shuffling:Key-value pairs are redistributed across nodes so that all pairs with the same key are sent to the same node. This step ensures data is grouped logically for the next stage.
Reducing:Each reducer processes the grouped data (by key), performing operations like summing, counting, or aggregating to generate a result.
Final Result:The reduced outputs from all nodes are combined into the final output dataset, ready for use or analysis.
-
Map: Mappers in containers execute the task using the data block in slave nodes. This is a part of the actual data manipulation for the job requested by the client. All mappers in the containers execute the tasks in parallel. The performance of the mapper depends on scheduling, data locality, programmer skills, container’s resources, data size and data complexity.
-
Sort/Spill: The output pair which is emitted by the mapper is called partition. The partition is stored and sorted in the key/value buffer in the memory to process the batch job. The size of the buffer is configured by resource tracker and when its limit is reached, the spill is started
-
Shuffle: The key/value pairs in the spilled partition are sent to the reduce nodes based on the key via the network in this step. To increase the network performance.
-
Merge: The partitions in the partition set are merged to finish the job. This step has usually been studied along with the shuffle step, such as in-memory with compression.
-
Reduce: The slave nodes process the merged partition set to make a result of the application. The performance of reduce depends on scheduling, locality, programmer skills, container resources, data size, and data complexity, as was the case in the map step. However, unlike in the map step, the reduce step can be improved by in-memory computing.
-
Output: The output of reduce nodes is stored at HDFS on the slave nodes.
3- Hadoop YARN
YARN (Yet Another Resource Negotiator) is a core component of Hadoop. Its main job is to manage resources and coordinate the execution of applications across the system. It ensures that all programs get the CPU and memory they need without conflicts.
Roles in Hadoop
-
Resource Management: Example: In MapReduce, the appropriate nodes are identified while ensuring balance in the system.
-
Application Execution: Example: Running a MapReduce program and monitoring it until it finishes.
-
Fault Tolerance: Example: YARN monitors nodes and restarts failed tasks.
4- Hadoop Common:
Hadoop Common is the foundation of the Hadoop ecosystem. It provides the essential tools, libraries, and utilities required by other Hadoop components (like HDFS and MapReduce) to function properly.
Key Roles
-
Provides Shared Libraries: Example: Libraries for file handling, logging, or network communication.
-
Manages Configuration: Example: Setting the block size in HDFS or specifying the replication factor.
-
Enables Communication Between Components: Example: Ensuring that a MapReduce job can access data stored in HDFS.
-
Provides Utility Tools: Example: Decompressing large files before processing them.
-
-
