Distributed data processing
Section outline
-
-
What It Means
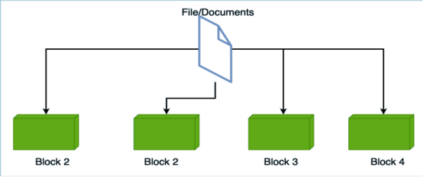
Instead of processing all data on a single computer, the work is divided among several machines (called nodes) connected in a network. Each node processes its part of the data and sends the results back to a central system or combines them for the final output.
Why It's Useful
-
Speeds up processing for large datasets.
-
Handles more data than a single machine can manage.
-
Improves fault tolerance: if one machine fails, others can continue working.
-
-