Replication
Résumé de section
-
-
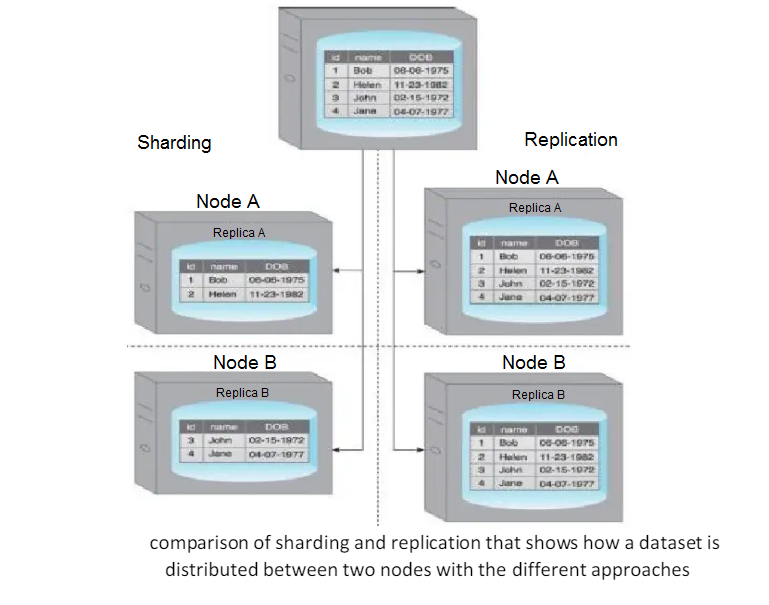
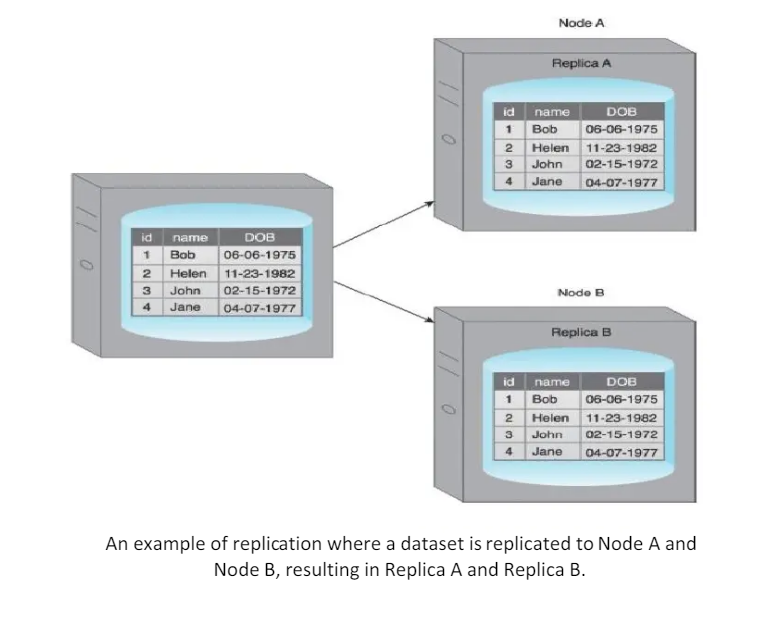
Replication stores multiple copies of a dataset, known as replicas, on multiple nodes.
Replication provides scalability and availability due to the fact that the same data is replicated on various nodes.
Fault tolerance is also achieved since data redundancy ensures that data is not lost when an individual node fails.
There are two different methods that are used to implement replication:
- master-slave
- peer-to-peer
-
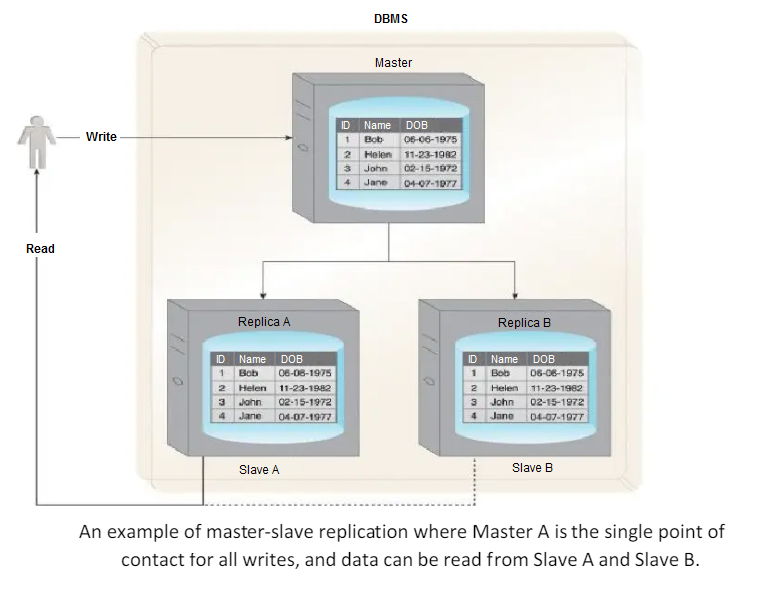
Nodes are arranged in a master-slave configuration, and all data is written to a master node.
Once saved, the data 1s replicated over to multiple slave nodes.
All external write requests, including insert, update and delete, occur on the master node, whereas read requests can be fulfilled by any slave node.
It is ideal for read intensive loads rather than write intensive loads since growing read demands can be managed by horizontal scaling to add more slave nodes.
Writes are consistent, as all writes are coordinated by the master node.
Write performance will suffer as the amount of writes increases.
If the master node fails, reads are still possible via any of the slave nodes.
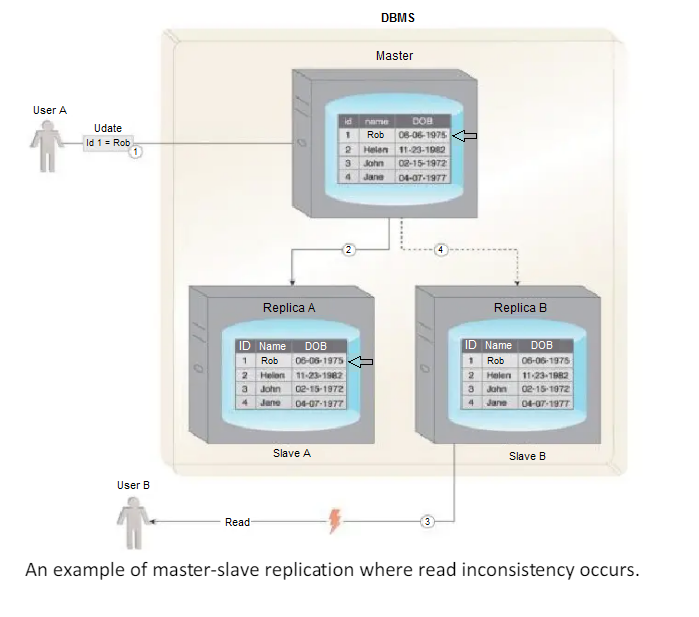
A slave node can be configured as a backup node for the master node.
Read inconsistency, which can be an issue if a slave node is read prior to an update to the master being copied to it.
To ensure read consistency, a voting system can be implemented where a read is declared consistent if the majority of the slaves contain the same version of the record.
Implementation of such a voting system requires a reliable and fast communication mechanism between the slaves.
- User A updates data.
- The data is copied over to Slave A by the Master.
- Before the data is copied over to Slave B, User B tries to read the data from Slave B, which results in an inconsistent read.
- The data will eventually become consistent when Slave B is updated by the Master.
-
With peer-to-peer replication, all nodes operate at the same level.
In other words, there is not a master-slave relationship between the nodes.
Each node, known as a peer, is equally capable of handling reads and writes.
Each write is copied to all peers.
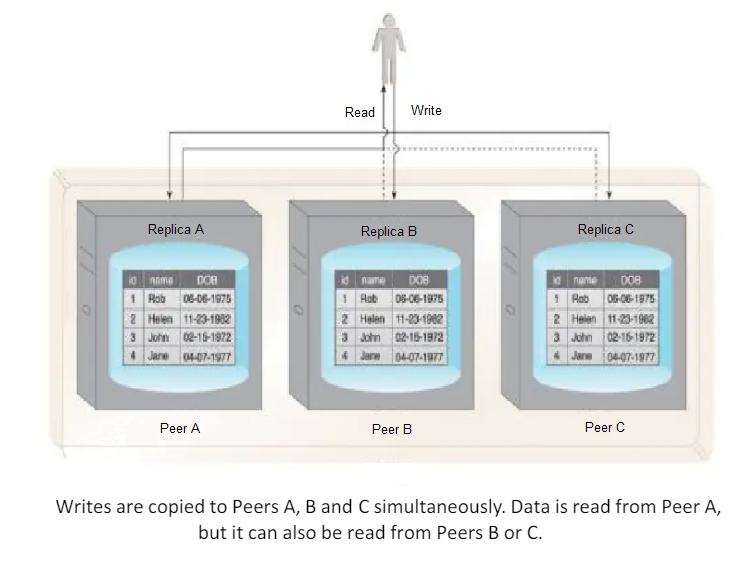
Peer-to-peer replication is prone to write inconsistencies that occur as a result of a simultaneous update of the same data across multiple peers.
This can be addressed by implementing either a pessimistic or optimistic concurrency strategy.
- Pessimistic concurrency is a proactive strategy that prevents inconsistency.
- It uses locking to ensure that only one update to a record can occur at a time. However, this is detrimental to availability since the database record being updated remains unavailable until all locks are released.
- Optimistic concurrency is a reactive strategy that does not use locking.
Instead, it allows inconsistency to occur with knowledge that eventually consistency will be achieved after all updates have propagated.
With optimistic concurrency, peers may remain inconsistent for some period of time before attaining consistency. However, the database remains available as no locking is involved.
Reads can be inconsistent during the time period when some of the peers have completed their updates while others perform their updates.
However, reads eventually become consistent when the updates have been executed on all peers.
To ensure read consistency, a voting system can be implemented where a read 1s declared consistent if the majority of the peers contain the same version of the record.
As previously indicated, implementation of such a voting system requires a reliable and fast communication mechanism between the peers.
Demonstrates a scenario where an inconsistent read occurs.
- User A updates data.
-
2.1. The data is copied over to Peer A.
2.2. The data is copied over to Peer B. - Before the data is copied over to Peer C, User B tries to read the data from Peer C, resulting in an inconsistent read.
- The data will eventually be updated on Peer C, and the database will once again become consistent.
-