Sharding
Résumé de section
-
-
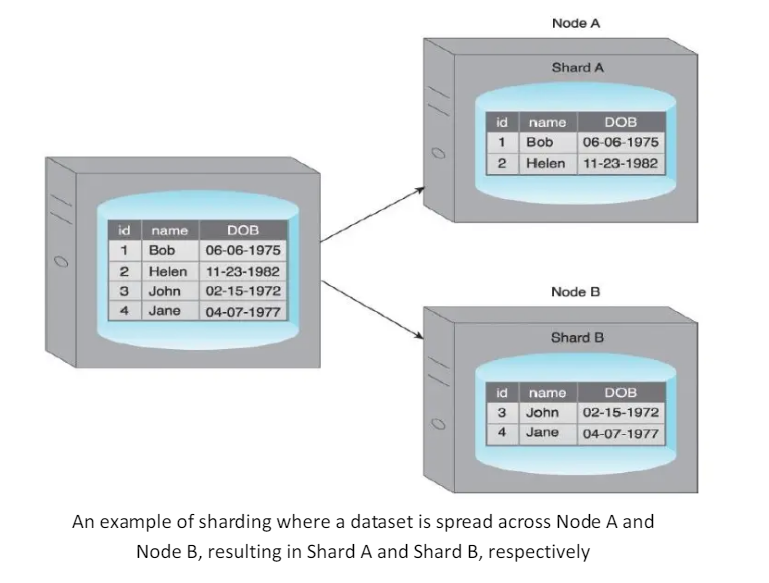
Sharding is the process of horizontally partitioning a large dataset into a collection of smaller, more manageable datasets called shards.
The shards are distributed across multiple nodes, where a node is a server or a machine.
Each shard
- It is stored on a separate node and each node 1s responsible for only the data stored on it.
- It shares the same schema, and all shards collectively represent the complete dataset.
-