Big Data Structuring
Section outline
-
-
A data warehouse is a centralized repository designed specifically for storing and
managing structured data. It is optimized for querying and analyzing large datasets,
making it essential for business intelligence (BI) and decision-making processes.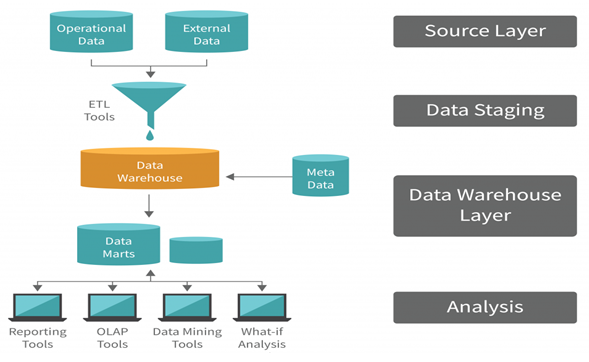
- Source Layer: This layer includes the operational data (such as transactional databases) and external data (e.g., third-party data, web data, etc.).
Collects raw data from multiple sources, which may have different formats, structures, or storage systems. - Data Staging: Data from the source layer is Extracted, Transformed, and Loaded (ETL process) into this staging area.
Handles data transformation, such as converting data types, handling missing values, or merging datasets. - Data Warehouse Layer: This is the central repository that stores the processed data in a structured format.
Allows querying large datasets efficiently.
Metadata: Provides information about the data, such as schema, relationships, and lineage.
Data Marts: Smaller subsets of the data warehouse focused on specific business domains, like sales or finance. - Analysis Layer: This layer is where users interact with the data warehouse to extract insights.
Provides tools and applications for analysis, reporting, and visualization.
- Source Layer: This layer includes the operational data (such as transactional databases) and external data (e.g., third-party data, web data, etc.).
-
A data lake is a centralized repository that stores large volumes of raw, unprocessed data in its native format, whether structured, semi-structured, or unstructured. It enables organizations to collect, manage, and process diverse datasets at scale, supporting a wide variety of use cases such as analytics, machine learning, and real-time processing.
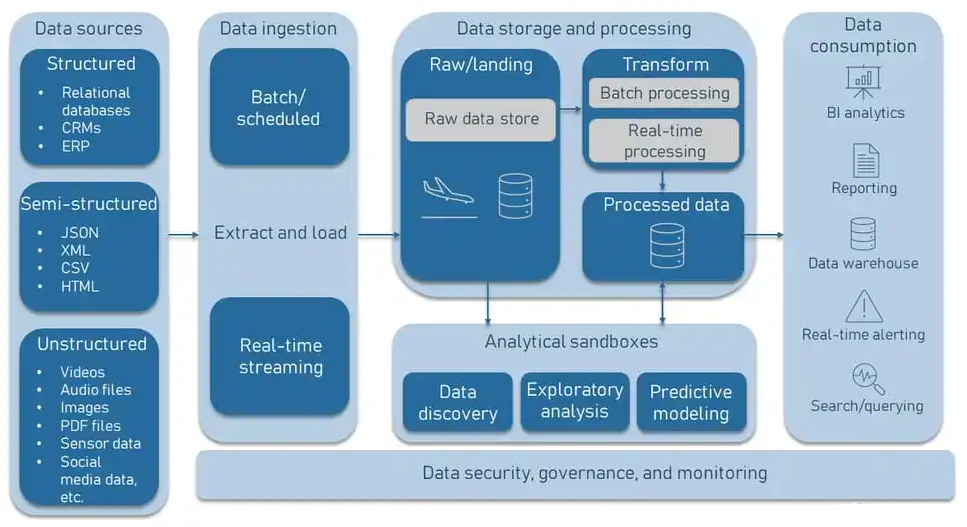
- Data Ingestion:
Data is gathered from multiple sources, including databases, streaming platforms, IoT devices, and APIs.
Tools like Apache Kafka, Flume, or AWS Glue facilitate ingestion.
- Data Storage:
Raw data is stored in its native format (e.g., CSV, JSON, images, or videos).
Common storage solutions include Amazon S3, Azure Data Lake, or Hadoop Distributed File System (HDFS).
- Data Processing:
Tools like Apache Spark or MapReduce process raw data for specific use cases.
Processing can be batch-oriented or real-time depending on the requirements.
- Data Analytics and Machine Learning:
Analysts and data scientists use tools like TensorFlow, PyTorch, or BI tools (Power BI, Tableau) to analyze data or build predictive models.
- Data Ingestion: