Chapter 2: Big Data Storage Concepts
Section outline
-
-
-
-
A cluster is a tightly coupled collection of servers, or nodes.
They servers usually have the same hardware specifications and are connected together
via a network to work as a single unit.
Each node in the cluster has its own dedicated resources, such as memory, a processor,
and a hard drive.
A cluster can execute a task by splitting it into small pieces and distributing their
execution onto different computers that belong to the cluster.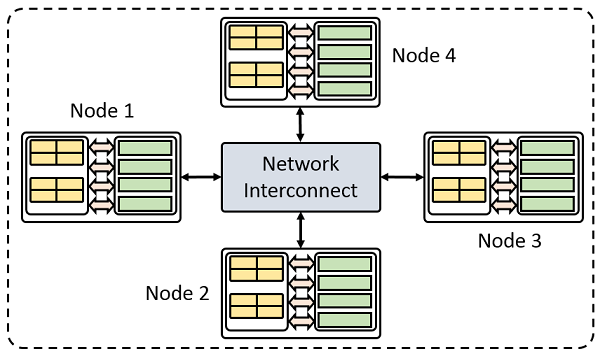
-
-
-
-
-
-
-
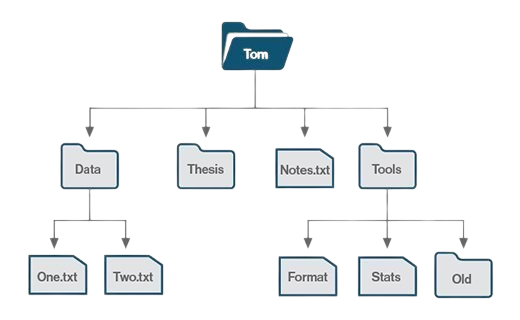
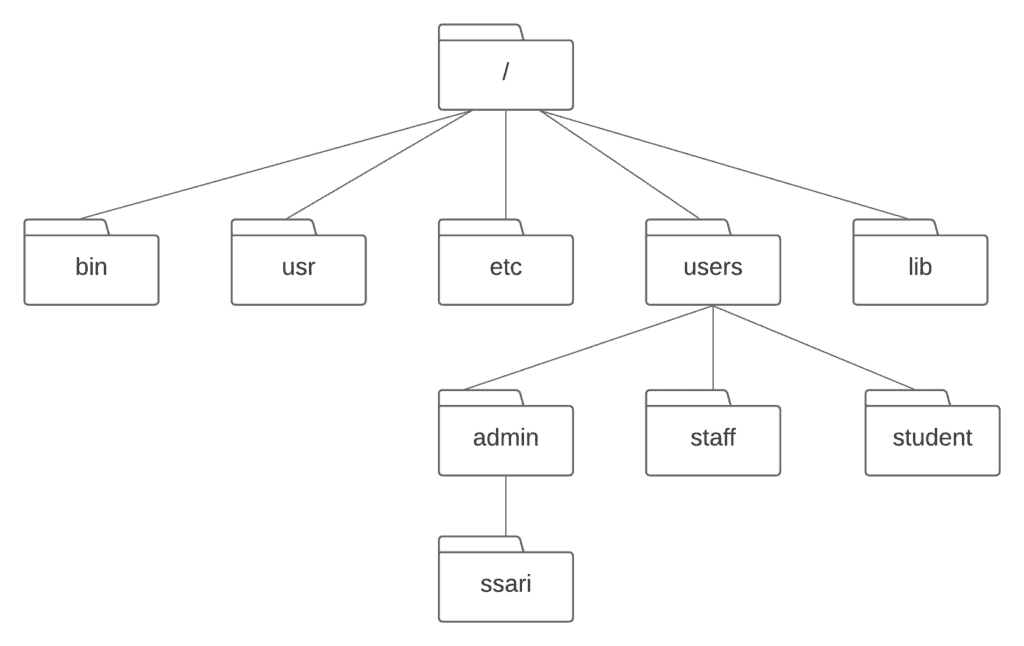
A file system provides a logical view of the data stored on the storage device and presents it as a tree structure of directories and files.
Operating systems employ file systems to store and retrieve data on behalf of applications.
-
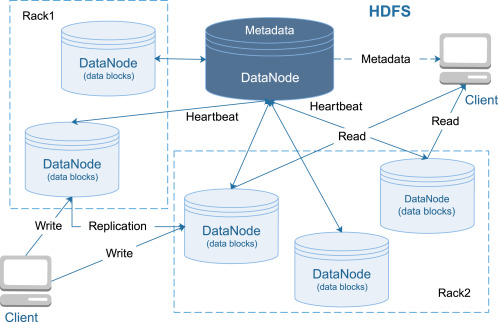
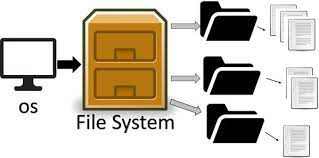
A distributed file system is a file system that can store large files spread across the nodes of a cluster.
To the client, files appear to be local; however, this is only a logical view.
Physically, the files are distributed throughout the cluster.
This local view is presented via the distributed file system and it enables the files to be accessed from multiple locations.
Examples include the Google File System (GFS) and Hadoop Distributed File System (HDFS).
-
-
-
-
-
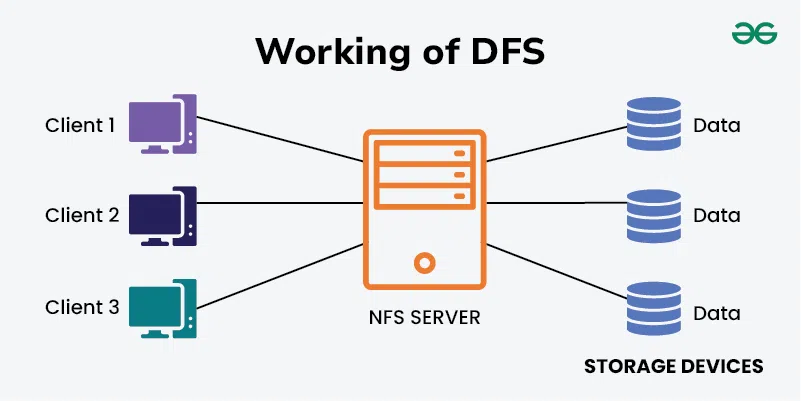
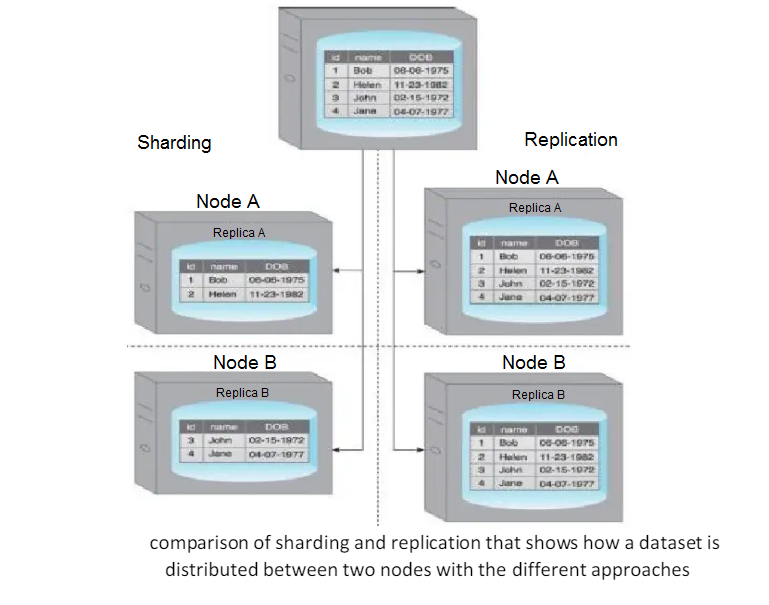
Sharding is the process of horizontally partitioning a large dataset into a collection of smaller, more manageable datasets called shards.
The shards are distributed across multiple nodes, where a node is a server or a machine.
Each shard
- It is stored on a separate node and each node 1s responsible for only the data stored on it.
- It shares the same schema, and all shards collectively represent the complete dataset.
-
-
-
-
-
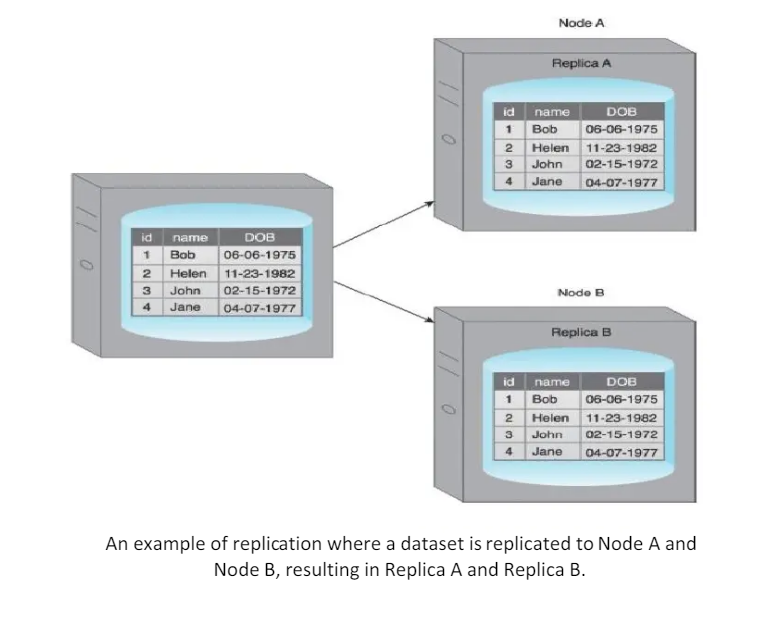
Replication stores multiple copies of a dataset, known as replicas, on multiple nodes.
Replication provides scalability and availability due to the fact that the same data is replicated on various nodes.
Fault tolerance is also achieved since data redundancy ensures that data is not lost when an individual node fails.
There are two different methods that are used to implement replication:
- master-slave
- peer-to-peer
-
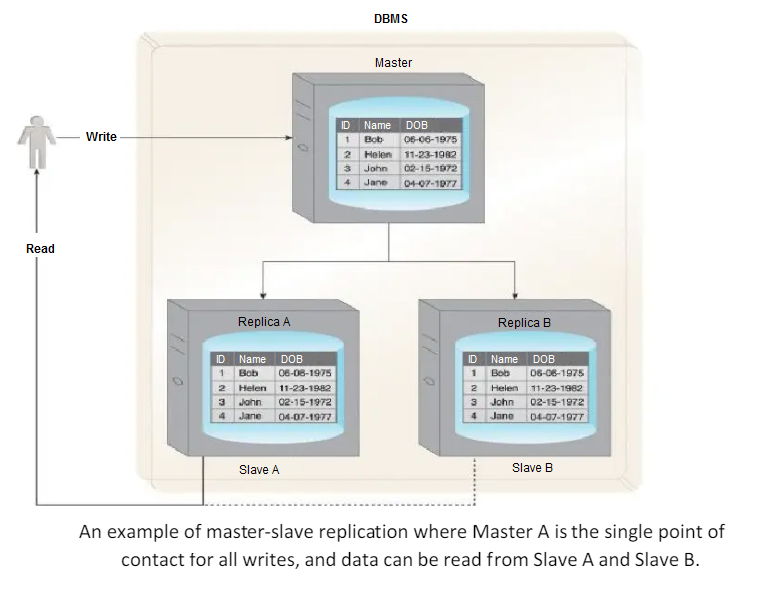
Nodes are arranged in a master-slave configuration, and all data is written to a master node.
Once saved, the data 1s replicated over to multiple slave nodes.
All external write requests, including insert, update and delete, occur on the master node, whereas read requests can be fulfilled by any slave node.
It is ideal for read intensive loads rather than write intensive loads since growing read demands can be managed by horizontal scaling to add more slave nodes.
Writes are consistent, as all writes are coordinated by the master node.
Write performance will suffer as the amount of writes increases.
If the master node fails, reads are still possible via any of the slave nodes.
A slave node can be configured as a backup node for the master node.
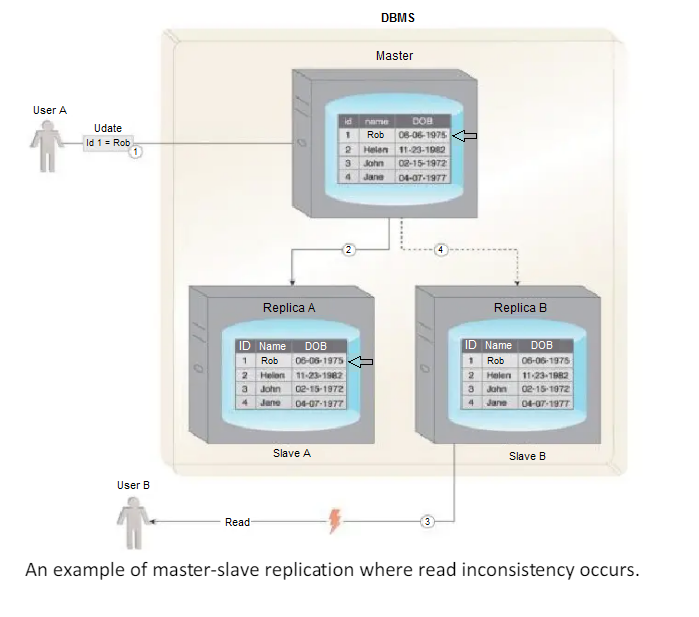
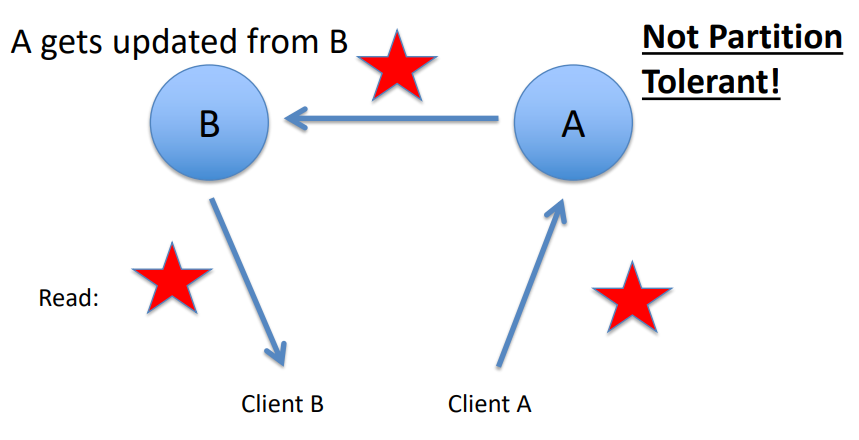
Read inconsistency, which can be an issue if a slave node is read prior to an update to the master being copied to it.
To ensure read consistency, a voting system can be implemented where a read is declared consistent if the majority of the slaves contain the same version of the record.
Implementation of such a voting system requires a reliable and fast communication mechanism between the slaves.
- User A updates data.
- The data is copied over to Slave A by the Master.
- Before the data is copied over to Slave B, User B tries to read the data from Slave B, which results in an inconsistent read.
- The data will eventually become consistent when Slave B is updated by the Master.
-
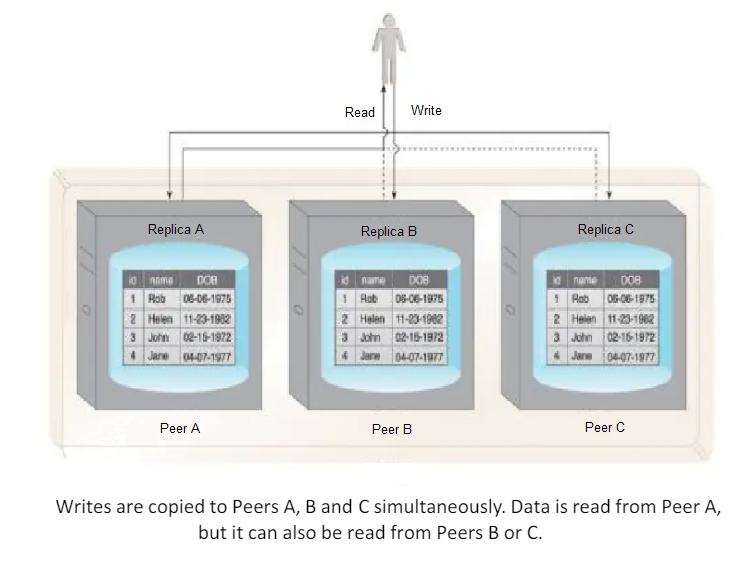
With peer-to-peer replication, all nodes operate at the same level.
In other words, there is not a master-slave relationship between the nodes.
Each node, known as a peer, is equally capable of handling reads and writes.
Each write is copied to all peers.
Peer-to-peer replication is prone to write inconsistencies that occur as a result of a simultaneous update of the same data across multiple peers.
This can be addressed by implementing either a pessimistic or optimistic concurrency strategy.
- Pessimistic concurrency is a proactive strategy that prevents inconsistency.
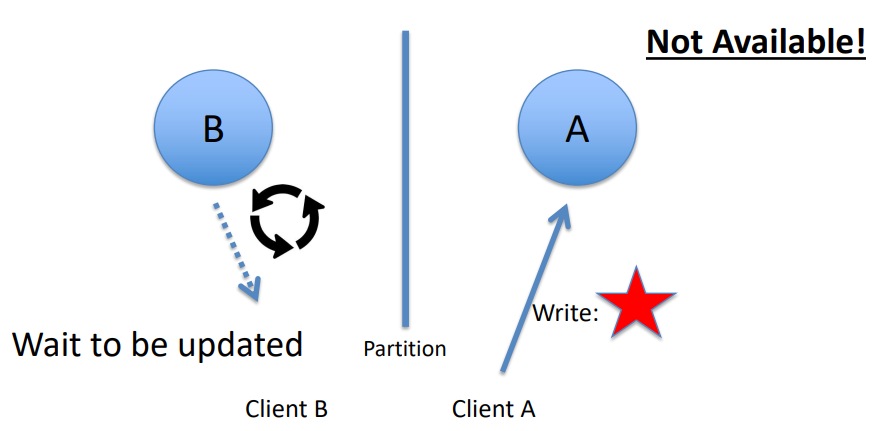
- It uses locking to ensure that only one update to a record can occur at a time. However, this is detrimental to availability since the database record being updated remains unavailable until all locks are released.
- Optimistic concurrency is a reactive strategy that does not use locking.
Instead, it allows inconsistency to occur with knowledge that eventually consistency will be achieved after all updates have propagated.
With optimistic concurrency, peers may remain inconsistent for some period of time before attaining consistency. However, the database remains available as no locking is involved.
Reads can be inconsistent during the time period when some of the peers have completed their updates while others perform their updates.
However, reads eventually become consistent when the updates have been executed on all peers.
To ensure read consistency, a voting system can be implemented where a read 1s declared consistent if the majority of the peers contain the same version of the record.
As previously indicated, implementation of such a voting system requires a reliable and fast communication mechanism between the peers.
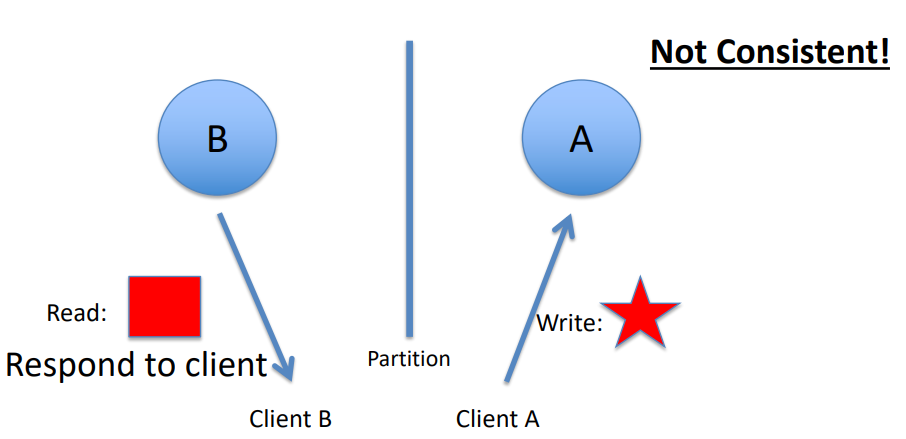
Demonstrates a scenario where an inconsistent read occurs.
- User A updates data.
-
2.1. The data is copied over to Peer A.
2.2. The data is copied over to Peer B. - Before the data is copied over to Peer C, User B tries to read the data from Peer C, resulting in an inconsistent read.
- The data will eventually be updated on Peer C, and the database will once again become consistent.
-
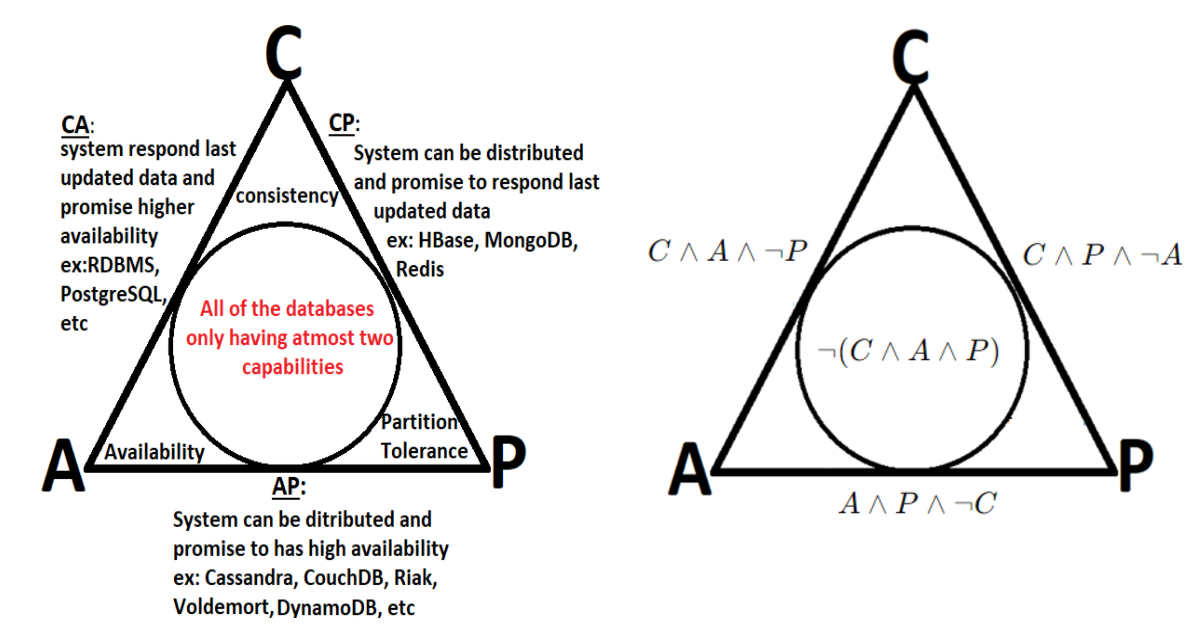
To improve on the limited fault tolerance offered by sharding, while additionally benefiting from the increased availability and scalability of replication, both sharding and replication can be combined.
-
-
-
-
-
-
-
-
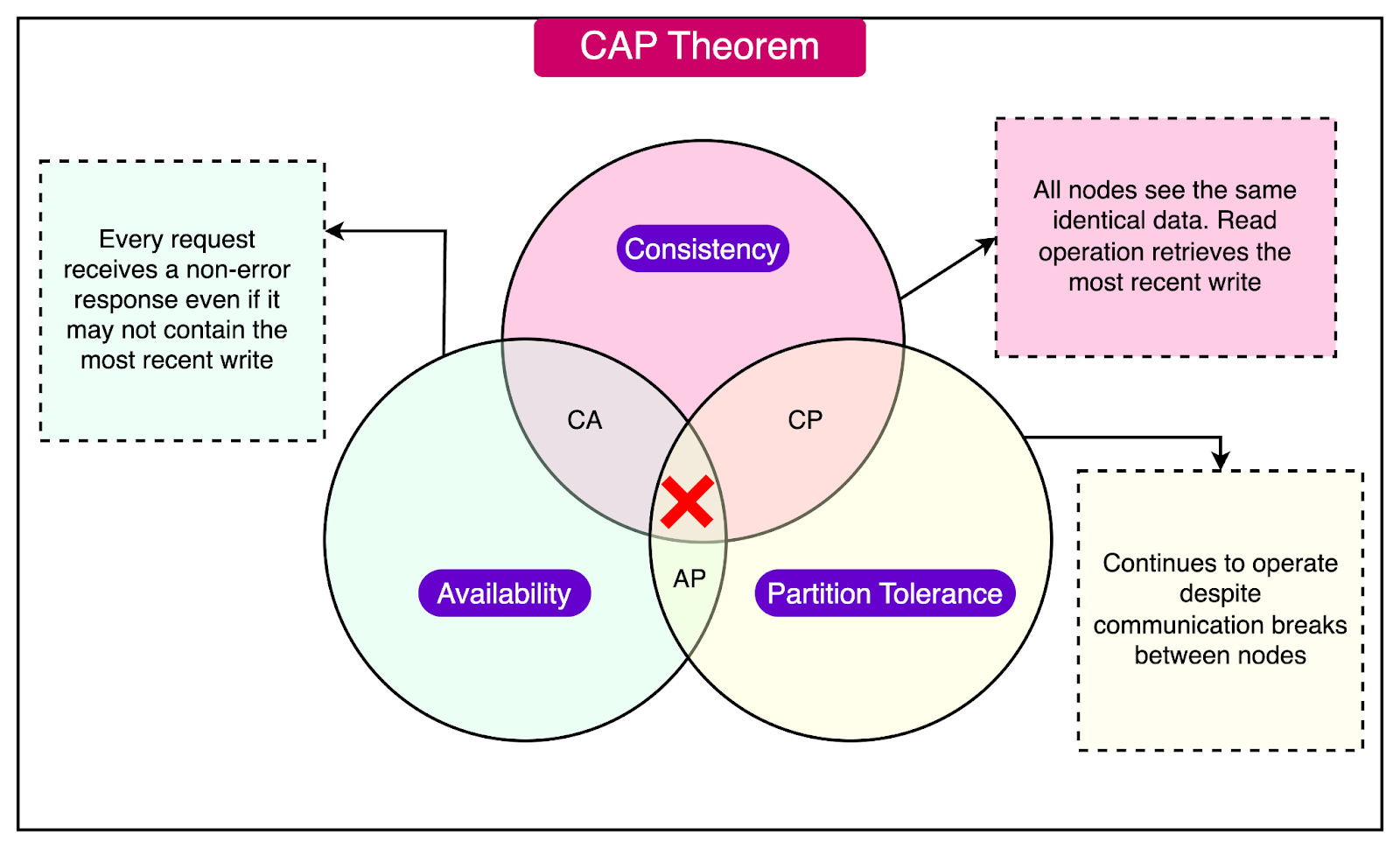
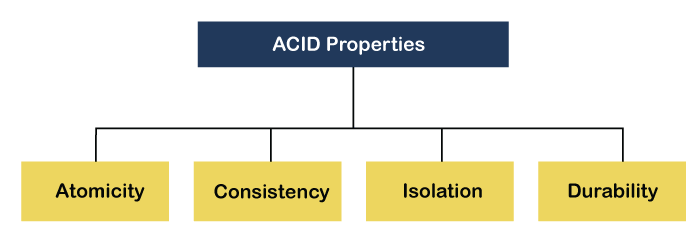
The ACID theorem refers to a set of properties that ensure reliable transaction processing in databases. These properties guarantee that database transactions are processed accurately, even in the presence of errors, power failures, or other disruptions. ACID stands for:
-
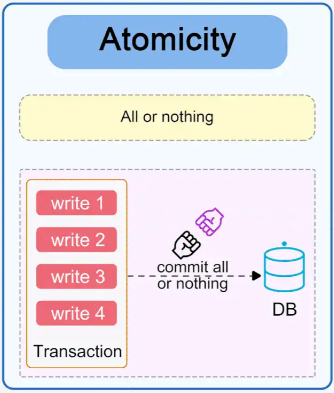
A transaction is treated as a single, indivisible unit. Either all its operations are completed successfully, or none are applied.
If any part of a transaction fails, the database remains unchanged, as if the transaction never occurred.
Example:
In a bank transfer, if money is debited from one account but cannot be credited to another due to an error, the entire transaction is rolled back.
-
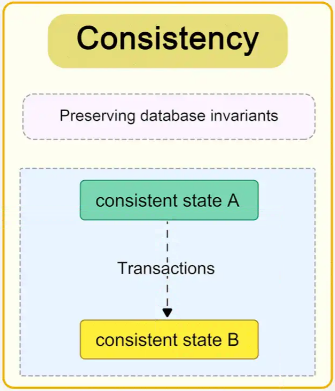
A transaction ensures that the database transitions from one valid state to another, maintaining all defined rules and constraints.
After a transaction completes, the database remains in a consistent state (e.g., constraints like unique keys, foreign keys, and checks are upheld).
Example:
In an inventory system, a transaction that decreases product stock cannot leave the stock in a negative state if the system enforces non-negative quantities.
-
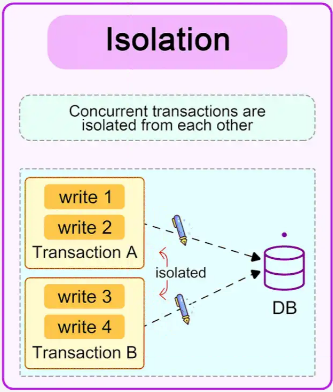
Transactions are executed independently and transparently. The operations of one transaction do not interfere with another.
Intermediate results of a transaction are not visible to other transactions until the transaction is committed.
Example:
Two customers cannot simultaneously purchase the last item in stock; the database ensures that one transaction completes before the other starts.
-
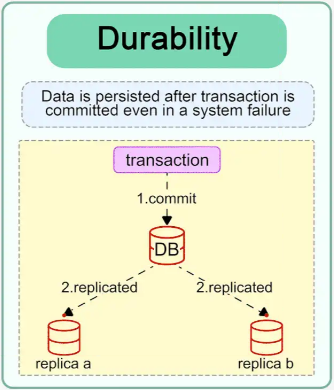
Once a transaction is committed, its results are permanent, even in the event of a system failure.
Changes made by a committed transaction are stored reliably (e.g., written to disk or replicated).
Example:
After confirming a flight booking, the reservation remains intact even if the server crashes immediately afterward.
-
-